How to Scrape Google Search Console Backlinks

Contents
As a webmaster or SEO specialist, conducting backlink audits is essential for maintaining a healthy website. To maintain a high ranking for your site and avoid potential penalties, it is crucial to identify and disavow toxic backlinks. However, manually exporting and correlating all backlink data from Google Search Console can be a daunting task.
For larger websites, the sheer volume of data can make the process of clicking and exporting data from GSC a time-consuming and impractical approach. Fortunately, there is a solution – web scraping. By utilising a web scraper, you can efficiently extract and analyze backlink data from GSC, allowing you to quickly identify and disavow any harmful links.
One effective way to scrape GSC backlinks is to use Python, a popular programming language for web development and data analysis. With Python, you can use the BeautifulSoup library to parse HTML and extract relevant information from web pages.
Google Search Console – Links Section
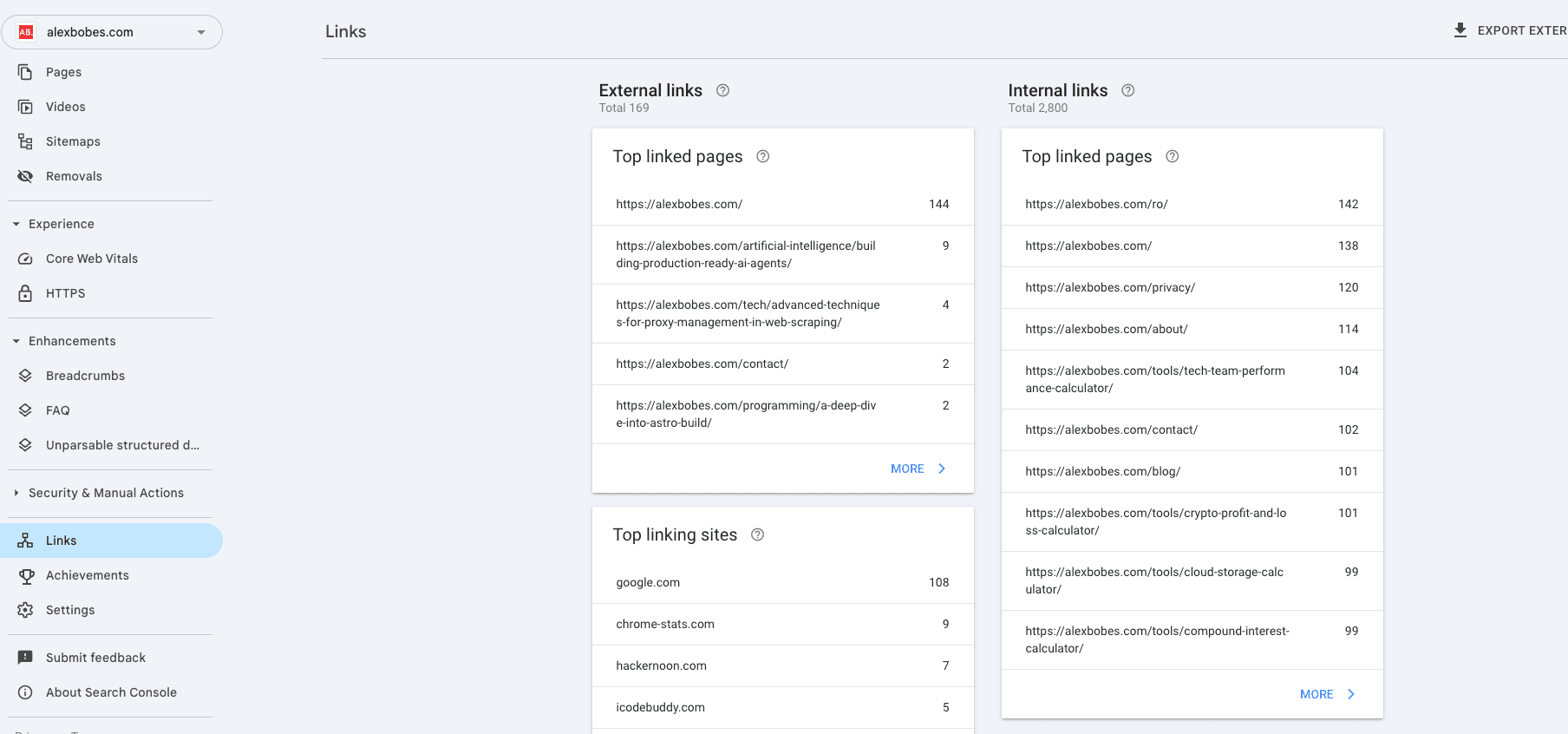
To begin, you'll need to install several packages using pip: bs4, requests, re, pandas, and csv. These packages will provide essential functionality for web scraping and data manipulation within Python.
pip install bs4 requests re pandas csv1. Emulate a user session
To start getting information about backlinks from Google Search Console, you need to simulate a normal user session. This can be done by opening the Links section in GSC through a web browser and selecting the Top linking sites section. When you get to this section, you'll need to right-click and choose "Inspect" to look at the page's source code.
Next, navigate to the network tab within the browser's dev tools and select the first URL that appears as a document type. This should be a request for a URL that follows this format: https://search.google.com/search-console/links?resource_id=sc-domain%3A{YourDomainName}
Click on the URL and look in the Headers tab for the Request Headers section, as shown in the image below:
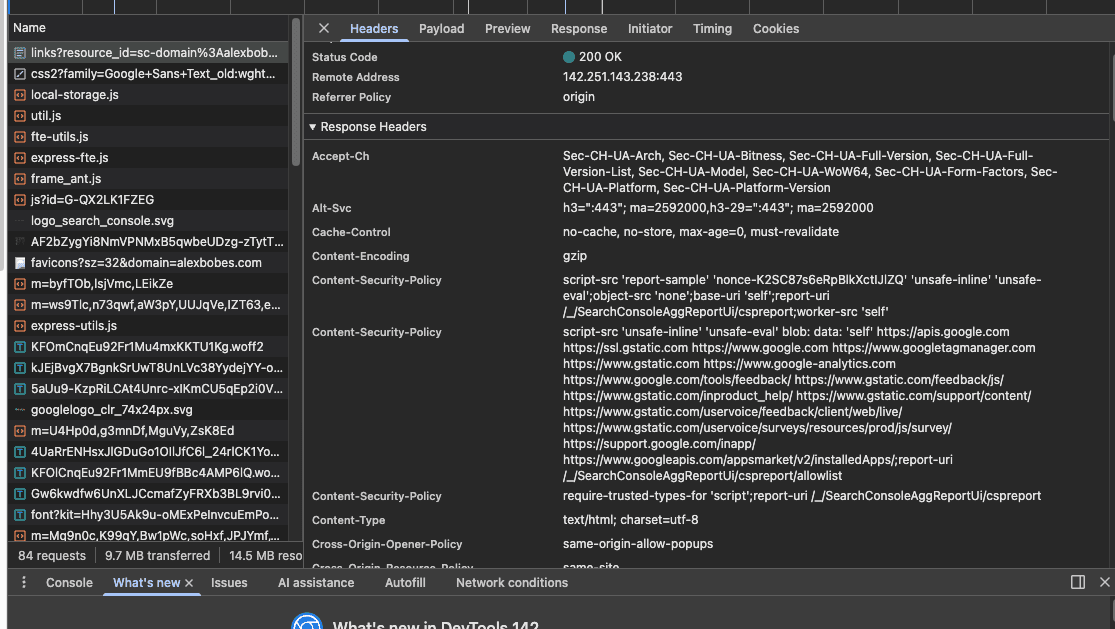
To successfully emulate a normal user session, we need to include the request information from the header in our Python requests.
The request header also has cookie information, which will be saved in a dictionary called cookies in Python's requests library. The remaining information from the header will be stored in a dictionary named "headers."
Essentially, we're taking the information from the header and creating two dictionaries, as shown in the code below. Remember to replace [your-info] with your actual information.
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
import csv headers = { "authority": "search.google.com", "method":"GET", "path":'"[your-info]"', "scheme":"https", "accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "accept-encoding":"gzip, deflate, br", "accept-language":"en-GB,en-US;q=0.9,en;q=0.8,ro;q=0.7", "cache-control":"no-cache", "pragma":"no-cache", "sec-ch-ua":"navigate", "sec-fetch-site":"same-origin", "sec-fetch-user":"?1", "upgrade-insecure-requests":"1", "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36", "x-client-data":"[your-info]", "sec-ch-ua":'" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"', "sec-ch-ua-mobile": "?0", "sec-fetch-dest": "document", "sec-fetch-mode": "navigate"
}
cookies = { "__Secure-1PAPISID":"[your-info]", "__Secure-1PSID":"[your-info]", "__Secure-3PAPISID":"[your-info]", "__Secure-3PSID":"[your-info]", "__Secure-3PSIDCC":"[your-info]", "1P_JAR":"[your-info]", "NID":"[your-info]", "APISID":"[your-info]", "CONSENT":"[your-info]", "HSID":"[your-info]", "SAPISID":"[your-info]", "SID":"[your-info]", "SIDCC":"[your-info]", "SSID":"[your-info]", "_ga":"[your-info]", "OTZ":"[your-info]", "OGPC":"[your-info]"
}The request header information displayed may vary depending on your individual case. Don't be concerned if there are differences, so long as you can generate the two necessary dictionaries.
After completing this step, execute the cell that contains the header and cookies information, as it is now time to move on to the first part of the actual script: collecting a list of referring domains that link back to your website.
Remember to replace [your-domain] with your actual domain name.
genericURL = "https://search.google.com/search-console/links/drilldown?resource_id=[your-domain]&type=EXTERNAL&target=&domain="
req = requests.get(genericURL, headers=headers, cookies=cookies)
soup = BeautifulSoup(req.content, 'html.parser')The URL provided above is the URL for the Top linking sites section. Please make sure to update it with the appropriate URL for your website.
To verify that you have successfully bypassed the login, test it by running the following code:
g_data = soup.find_all("div", {"class": "OOHai"})
for example in g_data: print(example) breakThe code above should produce a div element with the class "00Hai." If you can see this element, you may proceed.
2. Create a List of Referring Domains
The next step in this process will entail using Python and Pandas to generate a list of all the referring domains that link to your website.
g_data = soup.find_all("div", {"class": "OOHai"}) dfdomains = pd.DataFrame()
finalList = []
for externalDomain in g_data: myList = [] out = re.search(r'
(.*?(?=<))', str(externalDomain)) if out: myList.append(out.group(1)) finalList.append(myList) dfdomains = dfdomains.append(pd.DataFrame(finalList, columns=["External Domains"])) domainsList = dfdomains["External Domains"].to_list()The code provided above initialises an empty Pandas data frame, which will later be populated with external domains. The script works by scanning the entire HTML code and identifying all div elements with the "OOHai" class. If any such elements are found, the dfdomains DataFrame will be populated with the names of the external domains.
3. Extract Backlink information for each Domain
Moving forward, we will extract the backlink information for all domains, including the top sites that link to your page and the top linking pages (which corresponds to the third level of data in GSC, taking only the first value).
def extractBacklinks():
for domain in domainsList[:]:
url = (
"https://search.google.com/search-console/links/drilldown"
"?resource_id=[your-domain]"
f"&type=EXTERNAL&target={domain}&domain="
)
request = requests.get(url, headers=headers, cookies=cookies)
soup = BeautifulSoup(request.content, "html.parser")
for row in soup.find_all("div", {"class": "OOHai"}):
output = row.text
stripped_output = output.replace("", "")
domain_stripped = domain.split("https://")[1].split("/")[0]
print("---------")
print("Domain: " + domain)
print("---------")
url_secondary = (
"https://search.google.com/search-console/links/drilldown"
"?resource_id=[your-domain]"
f"&type=EXTERNAL&target={domain}&domain={stripped_output}"
)
request_secondary = requests.get(
url_secondary, headers=headers, cookies=cookies
)
soup_secondary = BeautifulSoup(
request_secondary.content, "html.parser"
)
for row in soup_secondary.find_all("div", {"class": "OOHai"}):
output_last = row.text
stripped_output_last = output_last.replace("", "")
break
with open(f"{domain_stripped}.csv", "a", newline="") as file:
writer = csv.writer(
file,
delimiter=",",
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
)
writer.writerow([domain, stripped_output, stripped_output_last])
extractBacklinks()
To address the issue of strange characters being returned by Beautiful Soup, we're using the Python .replace method to remove them.
After URL extraction, all URLs will be added to a .csv file in the script's directory.
Full code
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
import csv
headers = {
"authority": "search.google.com",
"method": "GET",
"path": "[your-info]",
"scheme": "https",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8,ro;q=0.7",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua": '"Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
"sec-ch-ua-mobile": "?0",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
"x-client-data": "[your-info]",
}
cookies = {
"__Secure-1PAPISID": "[your-info]",
"__Secure-1PSID": "[your-info]",
"__Secure-3PAPISID": "[your-info]",
"__Secure-3PSID": "[your-info]",
"__Secure-3PSIDCC": "[your-info]",
"1P_JAR": "[your-info]",
"NID": "[your-info]",
"APISID": "[your-info]",
"CONSENT": "[your-info]",
"HSID": "[your-info]",
"SAPISID": "[your-info]",
"SID": "[your-info]",
"SIDCC": "[your-info]",
"SSID": "[your-info]",
"_ga": "[your-info]",
"OTZ": "[your-info]",
"OGPC": "[your-info]",
}
genericURL = (
"https://search.google.com/search-console/links/drilldown"
"?resource_id=[your-domain]&type=EXTERNAL&target=&domain="
)
req = requests.get(genericURL, headers=headers, cookies=cookies)
soup = BeautifulSoup(req.content, "html.parser")
g_data = soup.find_all("div", {"class": "OOHai"})
for example in g_data:
print(example)
break
dfdomains = pd.DataFrame()
finalList = []
for externalDomain in g_data:
myList = []
out = re.search(r"(.*?(?=<))", str(externalDomain))
if out:
myList.append(out.group(1))
finalList.append(myList)
dfdomains = pd.DataFrame(finalList, columns=["External Domains"])
domainsList = dfdomains["External Domains"].to_list()
def extractBacklinks():
for domain in domainsList[:]:
url = (
"https://search.google.com/search-console/links/drilldown"
"?resource_id=[your-domain]"
f"&type=EXTERNAL&target={domain}&domain="
)
request = requests.get(url, headers=headers, cookies=cookies)
soup = BeautifulSoup(request.content, "html.parser")
for row in soup.find_all("div", {"class": "OOHai"}):
output = row.text
stripped_output = output.replace("", "")
domain_stripped = domain.split("https://")[1].split("/")[0]
print("---------")
print("Domain:", domain)
print("---------")
url_secondary = (
"https://search.google.com/search-console/links/drilldown"
"?resource_id=[your-domain]"
f"&type=EXTERNAL&target={domain}&domain={stripped_output}"
)
request_secondary = requests.get(
url_secondary, headers=headers, cookies=cookies
)
soup_secondary = BeautifulSoup(
request_secondary.content, "html.parser"
)
for row in soup_secondary.find_all("div", {"class": "OOHai"}):
output_last = row.text
stripped_output_last = output_last.replace("", "")
break
with open(f"{domain_stripped}.csv", "a", newline="") as file:
writer = csv.writer(
file,
delimiter=",",
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
)
writer.writerow([domain, stripped_output, stripped_output_last])
extractBacklinks()
Conclusion
Web scraping is a powerful technique that can be utilised to extract valuable data from Google Search Console. By leveraging Python and libraries such as BeautifulSoup and Pandas, you can efficiently collect backlink information for your website. While the process may seem complex at first, by following the steps outlined above, you can streamline the backlink auditing process and ensure the health of your website's SEO. By utilising this technique, you can easily identify toxic backlinks and take the necessary steps to disavow them, thereby improving your website's overall ranking and performance.
Related Articles
More articles you might find interesting

Best Practices for Optimizing Your React Application
React has emerged as a leading framework for building dynamic and responsive user interfaces.

The Science Behind Cumulative Layout Shift
In the vast ocean of metrics that measure web performance, Cumulative Layout Shift (CLS) emerges as a beacon highlighting visual stability. So,…

From Zero to Hero with SQL Joins
In the world of databases, SQL is our go-to for handling data. And when it comes to SQL, joins are a game-changer.…

Building a Slack Chatbot Leveraging the Power of OpenAI API
Hi there! I'm Alex Bobes, a tech enthusiast and CTO, currently in my second decade of tinkering with technology, unmasking the complexities…